트레이딩 모델 Feature Engineering Ablation: OHLC-only와 독립 알파 앙상블
JeTech agent의 입력 경로를 OHLC-only 중심으로 재정리하고, feature engineering보다 독립 알파 모델의 다양성과 가중 앙상블이 더 중요한지 검증한 로컬 진단 결과입니다.
요약
이 글의 결론은 단순하다. JeTech agent에서는 feature engineering을 더 늘리는 것보다, 같은 window_size x OHLC 입력을 여러 알고리즘과 여러 모델 용량으로 학습해 서로 다른 독립 alpha를 만들고, 검증된 모델들을 가중 앙상블로 운용하는 쪽이 더 낫다.
기존 JeTech agent의 production 학습/추론 입력은 순수 window_size x OHLC가 아니었다. 환경은 prev_close, open, high, low, close, liquidity_stress, target_exposure 7개 컬럼의 raw observation을 만들고, 대부분의 backbone은 이 값을 모델 내부에서 35개 engineered feature로 변환한 뒤 GRU/TCN/Transformer 계열 인코더에 넣었다.
이 리서치 이후 학습 코드는 신규 학습 기본값을 observation_schema=ohlc로 바꿨다. 즉 신규 env/model 입력은 window_size x 4(open, high, low, close)이고, 기존 7차원 checkpoint는 metadata가 없는 오래된 모델까지 legacy_v1 경로로 복원해 로딩 호환성을 유지한다. 이미 배포된 모델은 저장된 run config와 artifact shape를 기준으로 추론되므로 이 변경의 직접 대상이 아니다.
별도 로컬 ablation 실험에서는 같은 예측 모델에 두 입력만 비교했다.
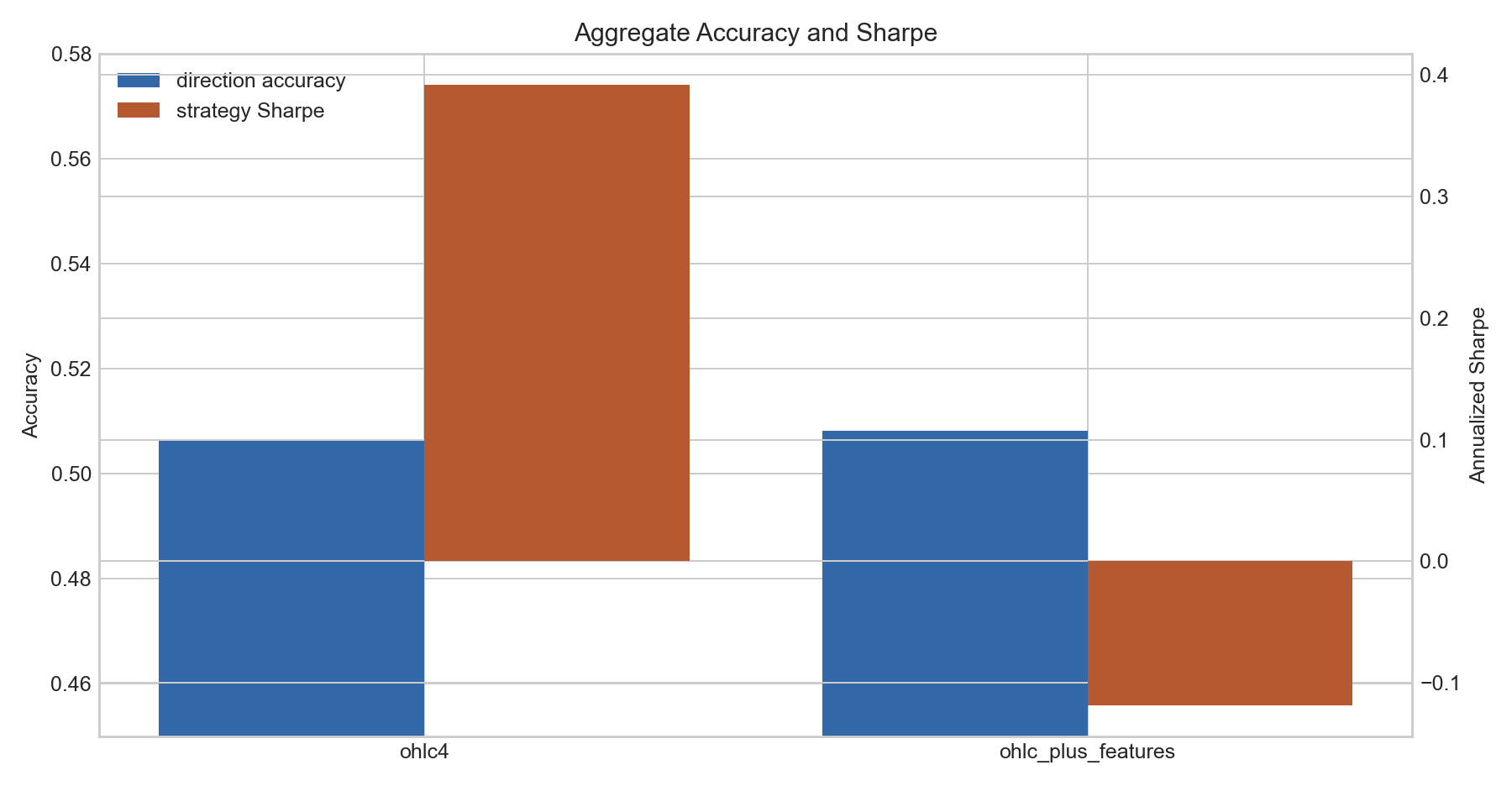
| Case | 입력 | Flatten dim | Accuracy | AUC | Strategy return | Strategy Sharpe | Max DD |
|---|---|---|---|---|---|---|---|
| Case 1 | window_size x OHLC | 256 | 50.62% | 0.5068 | +50.48% | +0.392 | -21.83% |
| Case 2 | window_size x (OHLC + engineered price features) | 2368 | 50.81% | 0.5138 | -11.21% | -0.118 | -41.77% |
이 결과는 “feature engineering이 무조건 무의미하다”가 아니라 “가격에서 파생한 feature를 많이 붙이면 약한 방향성 신호는 늘 수 있지만, trading outcome은 오히려 나빠질 수 있다”에 가깝다. 특히 Case 2는 AUC는 조금 높지만 확률이 과격하게 흔들려 flat 비중이 낮아지고 drawdown이 커졌다.
따라서 JeTech의 기본 학습 방향은 feature를 늘리는 것이 아니라 다음과 같이 둔다.
| 원칙 | 운영 해석 |
|---|---|
| 입력 단순화 | 신규 agent는 window_size x OHLC만 본다. |
| 모델 다양화 | 같은 입력으로 algo x backbone x version을 학습한다. version은 hidden dim/features dim/policy head 크기 차이를 의미한다. |
| 독립 alpha | feature set이 아니라 학습 알고리즘, inductive bias, model capacity, seed 차이로 alpha를 분산한다. |
| 앙상블 운용 | 단일 최고 모델보다 검증 통과 모델들의 가중 조합을 운용한다. |
| legacy 호환 | 기존 7차원 모델은 shape와 metadata가 맞는 legacy path로만 유지한다. |
현재 모델 입력 재조사
JeTech 코드 기준으로 입력 경로는 이번 수정 이후 아래처럼 나뉜다.
| 층 | 신규 기본 텐서 | legacy 텐서 | 코드 위치 |
|---|---|---|---|
| 가격 원천 | N x OHLC | N x OHLC | Yahoo/Binance/real eval frame, synthetic frame |
| 환경 observation | window_size x 4 | window_size x 7 | trading/synthetic/observations.py, trading/agents/env.py |
| neural encoder 입력 | window_size x 4 | window_size x 35 | trading/agents/models/base.py |
OHLC는 정확히 4개다. 7개라고 부른 것은 기존 환경이 모델에 넘기던 raw runtime observation 기준이었다. 이 7개는 feature engineering 이전의 model API 입력이고, feature extractor가 모델 내부에서 다시 35개 feature로 바꿨다.
이제 신규 모델에는 아래 값을 직접 넣지 않는다. 필요하면 reward, execution cost, gate, ensemble weighting 쪽에서 다루고, 모델 입력 자체는 가격 히스토리로 제한한다.
| 컬럼 | 이유 | 순수 가격 feature인가? |
|---|---|---|
prev_close | return/gap feature 계산을 편하게 하기 위해 넣었다. | OHLC window에서 모델이 직접 학습하게 둔다. |
liquidity_stress | synthetic regime/execution stress를 관측값에 넣기 위한 컬럼이었다. | 비용/슬리피지/reward에는 남기되 모델 입력에서는 제외한다. |
target_exposure | 현재 포지션 상태를 Markov state에 넣기 위한 값이었다. | action constraint와 execution state에서 관리하고 모델 입력에서는 제외한다. |
Algo x Model Feature Path
알고리즘은 feature를 직접 만들지 않는다. 알고리즘은 PPO/SAC/CQL처럼 업데이트 방식을 정하고, backbone이 observation을 어떻게 encode할지 결정한다.
| Algorithm family | Algorithms | Backbone/model | 신규 feature path | legacy path |
|---|---|---|---|---|
| SB3 on-policy | ppo, a2c, trpo | gru, lite_transformer, tcn, itransformer, patchtst, patchtsmixer | OHLC 4 -> backbone -> MLP policy/value heads | raw 7 -> engineered 35 |
| SB3 recurrent | rppo | same registered backbones + MlpLstmPolicy | OHLC 4 -> backbone -> recurrent policy/value path | raw 7 -> engineered 35 |
| SB3 off-policy |
Backbone별 feature 처리 방식은 아래와 같다.
| Backbone | 입력 변환 | Sequence 처리 | Pooling/출력 |
|---|---|---|---|
gru | OHLC 4 -> LayerNorm | GRU | 마지막 hidden -> projection |
lite_transformer | OHLC 4 -> Linear/GELU/LayerNorm | CLS token + positional embedding + TransformerEncoder | CLS와 token mean 평균 |
tcn | OHLC 4 -> Linear/GELU/LayerNorm | causal dilated TCN blocks | 0.7 * last + 0.3 * mean |
itransformer | OHLC 4 -> LayerNorm | feature별 과거 window를 token으로 뒤집어 TransformerEncoder | feature-token mean |
patchtst | OHLC 4 -> LayerNorm | Hugging Face PatchTSTModel |
이제 비교 단위는 명확하다. feature set은 고정하고, algorithm, backbone, version, seed, symbol이 alpha 다양성의 축이 된다.
실험 질문
이번 실험은 running RL 학습을 건드리지 않고, 로컬에서 feature representation 자체만 빠르게 진단했다.
질문은 하나다.
같은 모델과 같은 train/test split에서 window_size x OHLC만 넣은 모델과 window_size x (OHLC + feature)를 넣은 모델 중 어느 쪽이 out-of-sample trading metric이 나은가?
이번 실험은 RL gate가 아니라 supervised proxy다. 따라서 “후보 모델 등록 가능성”의 직접 증거는 아니고, feature engineering이 방향성 분류와 거래 성과에 어떤 영향을 주는지 보는 1차 진단이다.
실험 설계
| 항목 | 값 |
|---|---|
| Script | public/research/agent-feature-engineering-ablation-20260527/feature_ablation_experiment.py |
| Data source | Yahoo Finance daily OHLC |
| Period requested | 2018-01-01 to 2026-05-27 |
| Test period after chronological split | 대체로 2023-12 to 2026-05, SOL은 2024-08부터 |
| Symbols | BTCUSDT, ETHUSDT, SOLUSDT, XRPUSDT, DOGEUSDT, SPY, QQQ, COPPER, NATGAS, SILVER |
| Window | 64 bars |
| Target |
Aggregate Result
| Feature set | Rows | Accuracy | AUC | Log loss | Strategy return | Market return | Strategy Sharpe | Market Sharpe | Max DD | Flat ratio | Turnover |
|---|---|---|---|---|---|---|---|---|---|---|---|
ohlc4 | 7,329 | 50.62% | 0.5068 | 0.7804 | +50.48% | +63.54% | +0.392 | +0.370 | -21.83% | 15.15% | 0.905 |
ohlc_plus_features | 7,329 | 50.81% | 0.5138 | 1.9319 | -11.21% | +63.54% | -0.118 |
해석은 조심해야 한다. ohlc_plus_features가 Accuracy와 AUC는 조금 높다. 하지만 log loss가 크게 나빠졌고, threshold 기반 trading rule에서는 거의 항상 포지션을 잡는 쪽으로 기울었다. 그 결과 Sharpe와 drawdown은 OHLC-only보다 나쁘다.
즉, feature expansion은 분류 점수를 조금 개선했지만, “돈이 되는 확률”로 calibration되지는 않았다. 현재 agent 학습에서 flat이 많거나 one-sided exposure가 심한 현상도 이 문제와 연결될 수 있다. feature가 많아질수록 모델은 작은 통계적 패턴에 더 민감해지고, reward/gate가 그것을 충분히 벌하지 않으면 거래 행동이 불안정해진다.
Per-symbol Sharpe
| Symbol | OHLC-only Sharpe | OHLC+features Sharpe | 더 나은 입력 |
|---|---|---|---|
| BTCUSDT | +0.644 | +0.504 | OHLC-only |
| ETHUSDT | +0.605 | +0.236 | OHLC-only |
| SOLUSDT | +0.917 | -0.446 | OHLC-only |
| XRPUSDT | -0.115 | -0.312 | OHLC-only |
| DOGEUSDT | +0.409 | -0.153 | OHLC-only |
| SPY | +0.027 | +0.157 | OHLC+features |
| QQQ | +0.049 | +0.424 | OHLC+features |
| COPPER | +0.092 |
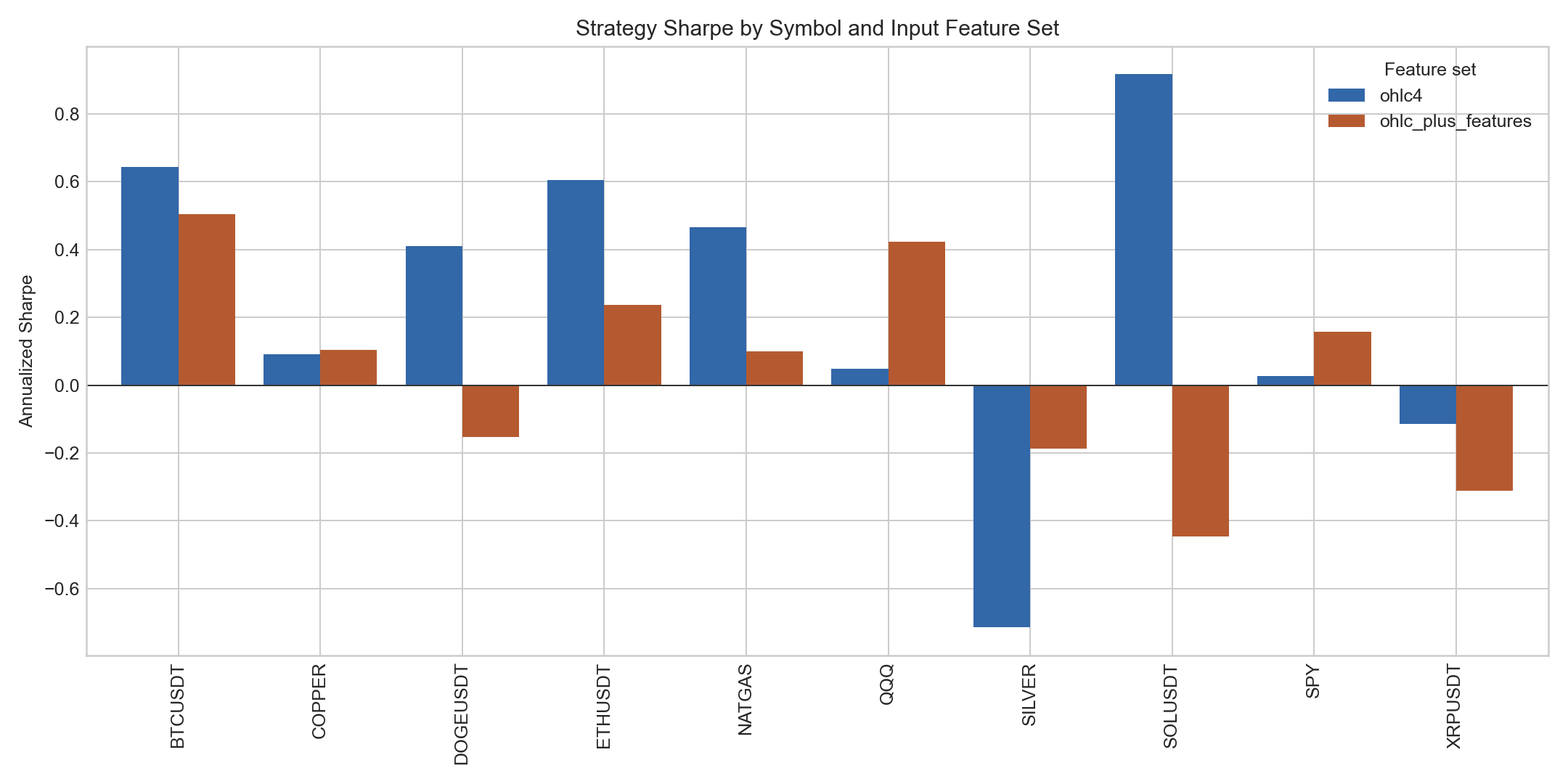
Crypto 쪽은 대체로 OHLC-only가 더 안정적이었다. ETF/metal 쪽 일부는 engineered feature가 Sharpe를 개선했다. 이건 feature engineering을 전체 universe에 한 번에 켜거나 끄기보다, asset class별/알고리즘별로 feature mode를 gate하는 쪽이 더 타당하다는 신호다.
문헌에서 얻은 기준선
이번 리서치에서 참고한 문헌은 크게 네 그룹으로 나뉜다.
| 주제 | 참고 문헌 | JeTech에 주는 의미 |
|---|---|---|
| 기술적 지표의 가능성과 한계 | Lo, Mamaysky, Wang 2000, Fama 1970 | 기술적 지표는 검정 가능한 price-history transformation이지, 그 자체로 alpha 보장은 아니다. out-of-sample test와 transaction cost가 핵심이다. |
| 금융 시계열 deep learning | Sezer et al. 2019 | 금융 예측 연구는 많지만 feature, split, leakage, cost 처리 차이가 커서 내부 ablation이 필요하다. |
| 단순 모델 vs 복잡 모델 | Zeng et al. 2023, TSMixer 2023 | 시계열에서는 복잡한 attention이 항상 이기지 않는다. 좋은 inductive bias와 단순 baseline이 강하다. |
| Patch/inverted backbone | PatchTST, iTransformer | JeTech의 PatchTST/iTransformer 계열은 feature-token/patch 설계와 잘 맞지만, feature expansion이 반드시 trading metric 개선으로 이어지지는 않는다. |
| 앙상블과 모델 다양성 | Nti, Adekoya, Weyori 2020, , |
결론
1. 현재 증거만 보면 feature engineering을 더 추가하는 것보다 window_size x OHLC 입력을 표준화하는 편이 낫다. 2. OHLC + engineered features는 aggregate AUC를 조금 올렸지만 Sharpe와 drawdown을 망쳤다. trading agent에서는 분류 점수보다 position calibration, turnover, drawdown이 더 중요하다. 3. 신규 학습 코드는 observation_schema=ohlc를 기본값으로 둔다. env와 model 모두 OHLC 4개만 입력으로 받는다. 4. 기존 배포 모델은 legacy 7차원 checkpoint로 유지한다. 저장된 run config가 없는 오래된 모델도 legacy_v1로 복원해 inference shape mismatch를 피한다. 5. 앞으로의 alpha 다양성은 feature set이 아니라 algo x backbone x version x seed x symbol에서 만든다. 6. version은 단순 번호가 아니라 모델 용량 축이다. 예를 들어 v1은 기본 64-dim 계열, v2는 96-dim/features dim과 더 큰 policy/value head를 쓰는 식으로 독립 alpha 후보를 만든다. 7. 운용은 단일 최고 모델에 베팅하기보다 candidate gate를 통과한 모델들의 가중 앙상블로 간다. 이 편이 feature engineering 추가보다 실제 운용 리스크를 줄이는 방향이다.
다음 작업 제안
| 우선순위 | 작업 | 이유 |
|---|---|---|
| P0 | 신규 missing-combo 학습을 OHLC-only preset으로 재시작 | 기존 7차원 feature path와 신규 4차원 path가 섞이지 않게 하기 위해서다. |
| P1 | v1/v2 등 parameter-size별 pass rate와 ensemble 기여도를 별도 집계 | 독립 alpha가 실제로 늘어나는지 확인해야 한다. |
| P1 | candidate 모델 weight를 개별 Sharpe만이 아니라 pairwise correlation/turnover까지 포함해 산정 | 서로 비슷한 모델 여러 개보다 낮은 상관의 모델 조합이 더 중요하다. |
| P2 | engineered feature는 별도 실험 브랜치에서만 비교 | 기본 학습 파이프라인이 다시 feature-heavy로 회귀하지 않게 한다. |